Advertisement
The way we evaluate large language models (LLMs) is shifting. There is growing recognition that most existing benchmarks don't fully capture the complexity or depth of what modern LLMs are intended to do. They measure surface-level performance, usually in English, and often rely on outdated datasets. But that's changing.
A new benchmark, AraGen, is part of a broader project called 3C3H, which is pushing the boundaries of how we think about LLM evaluation. It brings something long overdue: deeper context, cultural awareness, and a real challenge in the form of rich, multilingual understanding. This isn't just a technical tweak—it’s a rethink.
3C3H stands for Contextual, Culturally-Conscious, and Challenging Human-Generated evaluation. It’s a model evaluation approach that breaks away from typical multiple-choice or fill-in-the-blank questions. Instead, it uses content that mimics real-world complexity. That means longer context windows, nuanced interpretations, and cultural references that test more than language prediction. It tests understanding.

The 3C3H framework doesn’t just aim for a harder test. It introduces human-written prompts and responses that force the model to consider tone, style, and ambiguity—something few current evaluations address. It’s more grounded in how humans use language and less about how machines complete patterns. This matters because LLMs are now being used in areas like education, writing assistance, legal drafting, and research support, where surface accuracy isn’t enough.
What separates 3C3H is that it’s not about tricking the model. It’s about seeing how close its thinking can come to the human baseline, especially across different languages and cultural references. That’s where AraGen comes in.
AraGen is the Arabic component of the 3C3H benchmark. Arabic is a complex, morphologically rich language with diglossia (two primary forms: Modern Standard Arabic and dialects), and few high-quality benchmarks have properly addressed it until now. AraGen is built from scratch using human-written data, not scraped or auto-translated content. This is key because models often fail when dealing with nuanced, human-made content, especially in non-English languages.
What AraGen brings is range. It includes literary questions, historical context, political themes, philosophical problems, and logical puzzles—all written in Arabic, often involving long-form passages. These aren’t just trivia-style tests. They’re closer to how people read, interpret, and respond to content in everyday life. That makes it more accurate as a stress test for LLMs in real-world use.
The benchmark includes thousands of multiple-choice questions but with a twist. Each set involves multiple paragraphs, references outside the text, or reasoning that requires a higher-order understanding of the subject. AraGen isn't only testing Arabic fluency. It's asking the model to show insight, handle ambiguity, and be context-aware—all within a language many LLMs still struggle with.
This isn't just a new test. It’s a step toward creating culturally inclusive benchmarks that push models to understand more than just the dominant language patterns of the internet.
Alongside AraGen, there's an open leaderboard. This may seem like a standard move in the AI field, but the way it's structured says a lot. Instead of listing overall scores only, the leaderboard breaks down performance across dimensions such as question length, cultural depth, inference complexity, and domain diversity. This forces a more honest look at what the model is doing well—and where it's falling short.
The leaderboard isn’t just a scoreboard. It’s a living analysis of how different LLMs stack up across cultural and contextual lines. By highlighting weaknesses, it creates a path for improvement, not just bragging rights. It’s also publicly accessible, which puts more pressure on companies and research labs to be transparent with model capabilities.
Another feature is the inclusion of human baseline scores. This is essential because it grounds the entire evaluation. It helps keep the benchmark from becoming just another race for better numbers. It sets a real-world benchmark: how an educated human might respond. That shifts the goal from raw accuracy to human-level alignment.
The data from the leaderboard already shows something interesting. Some models that score high on standard English benchmarks drop significantly on AraGen. This reinforces the idea that real multilingual and cultural depth is still missing in many LLMs, even the ones that claim broad understanding. This isn't surprising, but now it's measurable.
The broader point of AraGen and 3C3H isn’t just to make things harder. It’s about relevance. Language models are now deeply woven into how we search, write, translate, and learn. If they’re only tested on simple, English-language questions, they’ll keep reflecting those limits. A benchmark like AraGen helps reveal blind spots.

This reframing matters in global education, healthcare communication, international research, and user-facing applications across continents. If LLMs are going to be trusted to generate useful and respectful responses in any setting, they have to understand more than just grammar. They need a sense of nuance. They need to manage tone, recognize bias, and process multiple perspectives.
AraGen, by focusing on Arabic, already challenges the bias baked into most LLM training data. It forces developers to think beyond scale and speed and start thinking about substance. Evaluation isn’t just about model performance. It’s a mirror that shows us what the model is missing—and what we still need to teach it.
This push toward a more grounded benchmark could change how LLMs are trained. Models that excel on AraGen will likely have richer pre-training data, better fine-tuning techniques, and more robust alignment methods. It could drive the next phase of LLM development away from just scaling and toward smarter, culturally-aware modeling.
LLM evaluation needs a shift, and AraGen shows it's already happening. The 3C3H approach moves beyond surface-level testing to focus on deeper understanding and cultural awareness. AraGen benchmark challenges models with Arabic, offering a real-world test of language and reasoning. Its leaderboard reveals performance gaps and drives progress. This isn’t just a dataset—it’s a new direction. If LLMs are meant to serve diverse users globally, benchmarks like AraGen must become the norm, not the exception.
Advertisement

How to run LLM inference on edge using React Native. This hands-on guide explains how to build mobile apps with on-device language models, all without needing cloud access
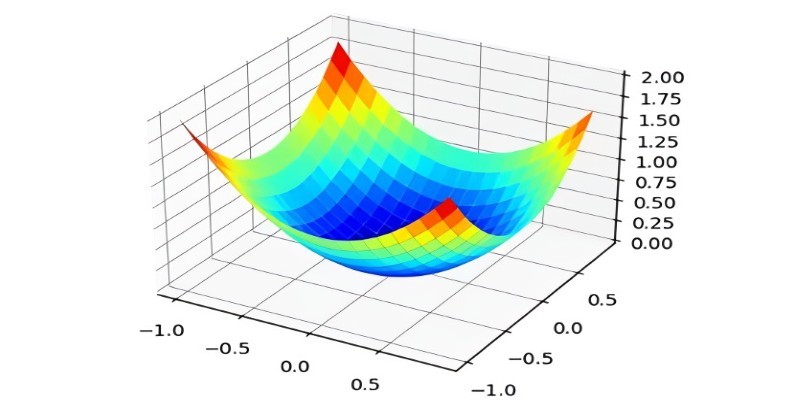
What the Adam optimizer is, how it works, and why it’s the preferred adaptive learning rate optimizer in deep learning. Get a clear breakdown of its mechanics and use cases

What data annotation is, why it matters in machine learning, and how it works across tools, types, and formats. A clear look at real-world uses and common challenges

Hugging Face and JFrog tackle AI security by integrating tools that scan, verify, and document models. Their partnership brings more visibility and safety to open-source AI development

Discover the Playoff Method Prompt Technique and five powerful ChatGPT prompts to boost productivity and creativity

How Open-source DeepResearch is reshaping the way AI search agents are built and used, giving individuals and communities control over their digital research tools

Explore the Rabbit R1, a groundbreaking AI device that simplifies daily tasks by acting on your behalf. Learn how this AI assistant device changes how we interact with technology
How Math-Verify is reshaping the evaluation of open LLM leaderboards by focusing on step-by-step reasoning rather than surface-level answers, improving model transparency and accuracy
How temporal graphs in data science reveal patterns across time. This guide explains how to model, store, and analyze time-based relationships using temporal graphs

How stochastic in machine learning improves model performance through randomness, optimization, and generalization for real-world applications
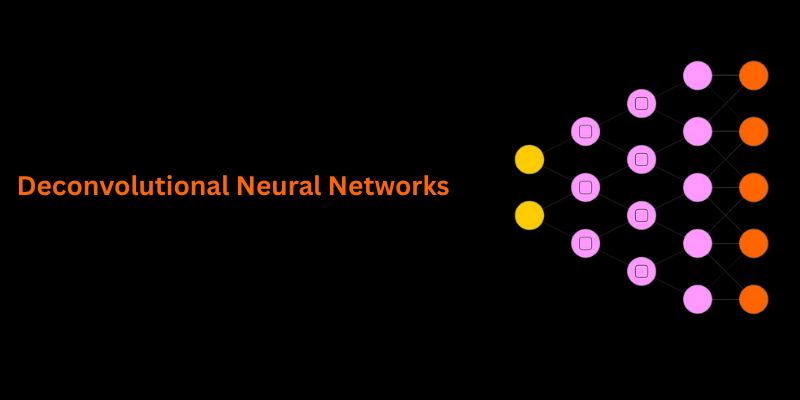
Understand how deconvolutional neural networks work, their roles in AI image processing, and why they matter in deep learning

AI interference lets the machine learning models make conclusions efficiently from the new data they have never seen before