Advertisement
We use search tools daily without giving them much thought. They fetch answers in milliseconds, sort through oceans of content, and surface just what we need. But have you ever wondered how these agents are built, what they learn from, or who controls what they prioritize? Most people don't. And that’s the problem.
As search becomes more embedded in how we work and think, the question of who owns and guides these systems becomes harder to ignore. Open-source DeepResearch offers a way to change that, making search agents accessible, inspectable, and modifiable by anyone—not just a few companies behind closed doors.
DeepResearch isn't a specific product. It refers to using AI search agents that dig far beyond keyword matches. These systems don't just point you to documents—they attempt to understand what you're asking and find relevant, context-aware answers. They're often built on large language models and fine-tuned search stacks that use document embeddings, retrieval pipelines, ranking models, and natural language reasoning.
So far, the most effective versions of these tools have been locked behind proprietary systems. If you’re using AI-powered research today, chances are it’s coming from a handful of platforms with little transparency. You can’t peek under the hood. You can't rewire the logic, change the priorities, or ensure it's working in a way that fits your needs rather than someone else’s goals.
This is where open-source DeepResearch matters. Instead of being limited to major platforms' search methods and models, open-source initiatives allow developers, researchers, and even curious individuals to build their search agents using freely available code, datasets, and model weights. That shifts the balance of control back toward users.
Open-source DeepResearch is about freeing the machinery of search. It allows people to understand and influence how their search tools work. That transparency brings several advantages.

First, it improves trust. When you can audit the code, check the sources, and see how results are ranked, it's easier to spot bias, mistakes, or gaps. An open-source model lets you adjust if a search agent prioritizes academic sources over blog posts or excludes non-English material. Closed systems offer no such control.
Second, it helps with experimentation. Want to build a search engine that works well on legal texts, medical papers, or obscure scientific archives? Open-source tools let you do that without needing millions in infrastructure. Projects like Haystack, RAG frameworks, or LlamaIndex allow setting up a capable research agent on your machine in a few days, sometimes hours.
Third, it fosters collaboration. Communities shape open projects, which means bugs are found faster, features are developed based on real needs, and models improve through shared experience. Commercial timelines don't bind these communities, so they can focus on quality, performance, and ethics without a quarterly report.
Finally, it’s about longevity. Closed search systems can be shut down, changed without notice, or become paywalled. Open systems last as long as people care about them. That's good for research, education, and public knowledge, not just for individual users.
Despite its promise, open-source DeepResearch isn't without its challenges. The first is infrastructure. While the code may be free, running a useful search agent—especially one powered by large models—takes computing. This can be expensive or technically demanding for individuals or small teams.
Another issue is usability. Open-source tools often assume technical fluency. To get things working well, you might need to write Python scripts, set up databases, or fine-tune models. That can be a high barrier for non-developers. Documentation is improving, but the learning curve is still real.
Data quality is another concern. A good search agent depends on a strong corpus of source documents. Getting, cleaning, and maintaining this data isn’t trivial. While some open projects provide datasets, coverage is patchy, especially for non-English content or niche domains.
Then, there's the question of ranking and relevance. Even with a smart model, search results need to be ordered meaningfully. That often involves fine-tuning, feedback loops, and heuristics—areas where closed systems still have a head start. But with enough community input and experimentation, open projects are catching up fast.
Legal and ethical concerns also play a role. Training or fine-tuning on certain data may raise copyright or privacy issues. And once a search agent is out in the wild, how do you handle misinformation, spam, or toxic content? Open systems don’t have the moderation layers built into commercial platforms, which can be both a strength and a weakness.
The direction of the search isn't fixed. It depends on what we build, use, and support. Open-source DeepResearch offers an alternative to centralized systems—not as a sudden replacement, but as a way to let people shape tools around their needs.

More lightweight, local search agents may emerge in the coming years. They will run on personal machines and be tuned to specific fields like climate science, legal research, or policy. They'll likely use open models like Mistral or LLaMA paired with frameworks like LangChain or Jina. Some will focus on summarization, others on multilingual content or combining search with memory.
This goes beyond software. With limited resources, open search agents can support citizen science, archives, journalism, or education. They can also uplift local knowledge and underrepresented voices that major platforms often miss.
Freeing our search tools means accepting many perspectives and approaches. It's not about waiting for a single system to define relevance—it's about building our own. That's not just technical work—it's social.
Open-source DeepResearch allows people to shape search rather than rely on closed systems. Sharing tools, models, and ideas encourages collaboration and flexibility. It opens the door to more meaningful, transparent research tools built by and for users. As this movement grows, search becomes less about control and more about shared knowledge—and that shift can change how we explore information entirely.
Advertisement

AI interference lets the machine learning models make conclusions efficiently from the new data they have never seen before

How Arabic leaderboards are reshaping AI development through updated Arabic instruction following models and improvements to AraGen, making AI more accessible for Arabic speakers

A simple and clear explanation of what cognitive computing is, how it mimics human thought processes, and where it’s being used today — from healthcare to finance and customer service

Natural language generation is a type of AI which helps the computer turn data, patterns, or facts into written or spoken words
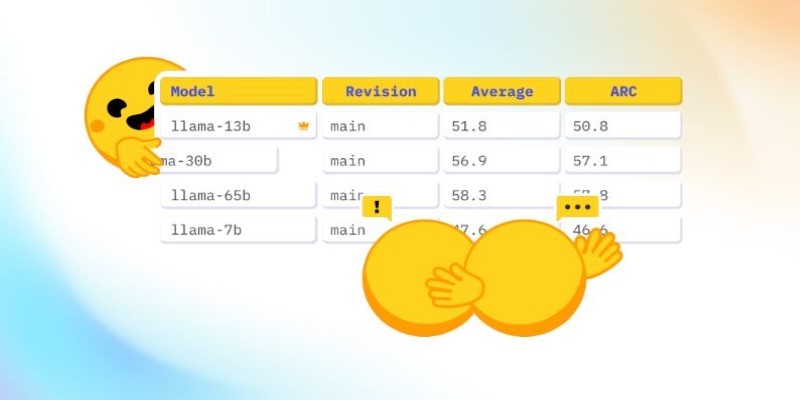
How Math-Verify is reshaping the evaluation of open LLM leaderboards by focusing on step-by-step reasoning rather than surface-level answers, improving model transparency and accuracy

How AI-powered earthquake forecasting is improving response times and enhancing seismic preparedness. Learn how machine learning is transforming earthquake prediction technology across the globe
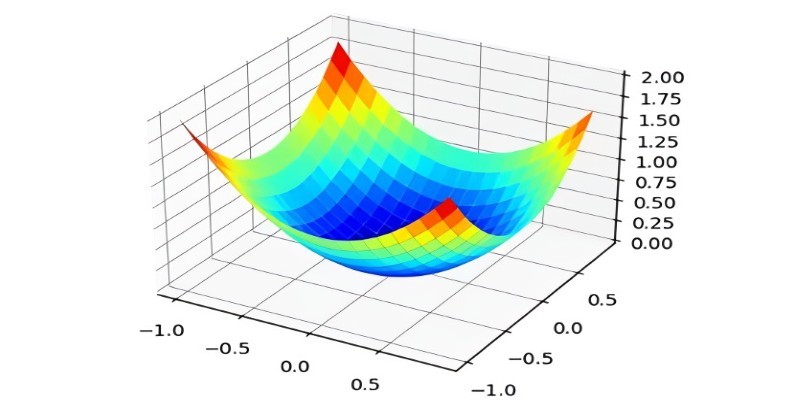
What the Adam optimizer is, how it works, and why it’s the preferred adaptive learning rate optimizer in deep learning. Get a clear breakdown of its mechanics and use cases
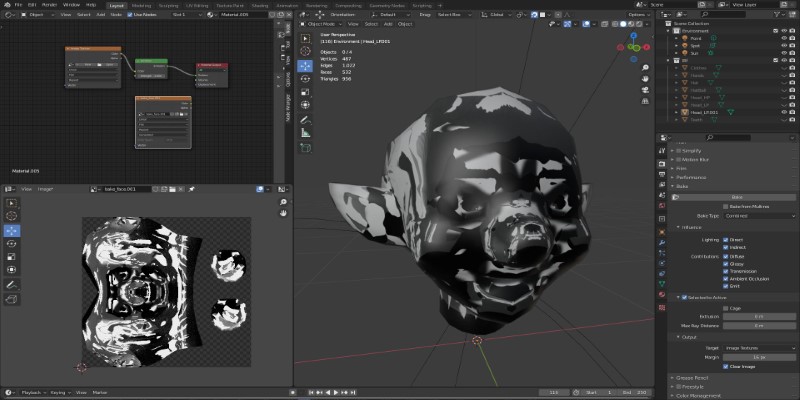
Learn how to bake vertex colors into textures, set up UVs, and export clean 3D models for rendering or game development pipelines

Explore the Rabbit R1, a groundbreaking AI device that simplifies daily tasks by acting on your behalf. Learn how this AI assistant device changes how we interact with technology
How temporal graphs in data science reveal patterns across time. This guide explains how to model, store, and analyze time-based relationships using temporal graphs

Looking to master SQL concepts in 2025? Explore these 10 carefully selected books designed for all levels, with clear guidance and real-world examples to sharpen your SQL skills

How LLM evaluation is evolving through the 3C3H approach and the AraGen benchmark. Discover why cultural context and deeper reasoning now matter more than ever in assessing AI language models