Advertisement
AI has moved quickly from lab experiments to critical tools embedded in daily apps, enterprise platforms, and infrastructure. But while the technology has scaled, its security posture hasn’t kept up. A major challenge is the opacity around model development and deployment. Users often don’t know who built a model, what data it was trained on, or whether it’s vulnerable to manipulation.
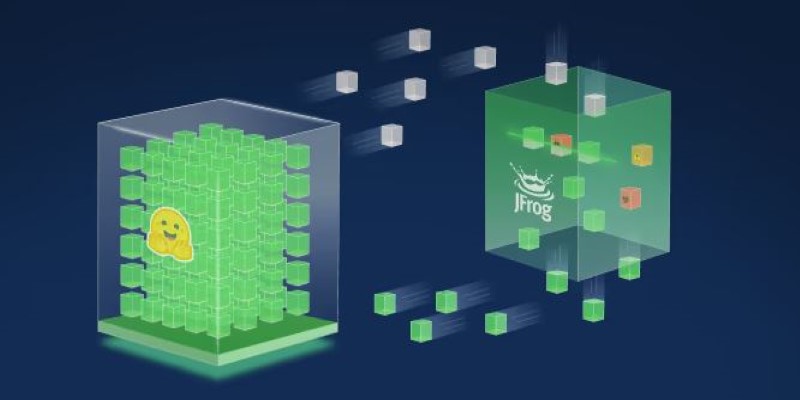
That gap is exactly what Hugging Face and JFrog are now trying to close. Their new collaboration is focused on bringing more clarity, verification, and traceability into the AI ecosystem—starting with open-source models and expanding across the board.
Most AI models, even if you share them publicly, come in a black box. You may be able to download a few lines of description, but you don't have much else. Questions such as whether the model has been scanned for malware, grabs unseen data from unseen sources, or has been trained on biased or faked datasets are usually unanswered. This is important because malicious actors can conceal malicious code or tainted data within models, just as in software packages. The increased utilization of open-source models raises this threat, particularly as individuals download and execute them without an official security procedure.
At the same time, many organizations are pushing to adopt AI faster—sometimes without the checks that traditional software would undergo. Developers and engineers may pull a model from a public repository, integrate it into a pipeline, and deploy it to production systems without knowing what's under the hood. This leaves gaps that are hard to detect and even harder to fix.
For years, the conversation around AI has focused on performance, accuracy, and speed. But as models move into high-stakes environments—like healthcare, finance, and public infrastructure—the need for transparency becomes just as important. Without a clear view of how a model was built, what it contains, or how it behaves in edge cases, there’s no way to fully trust it.
Transparency is also a prerequisite for accountability. If something goes wrong—say, a model makes a harmful recommendation or leaks private information—organizations need to trace their history to understand what failed. That trail often disappears without version control, dependency tracking, and metadata.
Transparency means providing clear documentation, origin data, reproducibility details, and security scans. It's not about over-regulating developers but rather giving them better tools to understand what they’re working with. Hugging Face and JFrog address this head-on by embedding transparency into the model lifecycle, not treating it as an afterthought.
Hugging Face already runs one of the world's most widely used model hubs, where developers share everything from fine-tuned transformers to cutting-edge research experiments. JFrog, on the other hand, specializes in software supply chain management, with tools that help developers scan, validate, and manage software artifacts securely.
Now, the two are combining forces. Through this partnership, models shared on Hugging Face will carry more metadata—automatically pulled and verified—about their origin, training data, dependencies, and changes. JFrog is bringing tools that scan models for known vulnerabilities and potential risks. This goes beyond just a model's file; it includes checking its environment files, dependencies, and embedded scripts.
This metadata is stored and published in ways developers can access and review. For example, when downloading a model, users can see a security "scorecard" or trust report—standard for open-source code libraries but nearly unheard of for open-source models. It’s a small but significant step toward making AI artifacts as traceable as traditional software packages.
What’s also changing is the level of integration. JFrog’s tools are being embedded directly into Hugging Face's backend. That means security checks won't depend on developers' optional steps—they'll happen automatically. Over time, this will create a baseline of transparency and make it harder for dangerous models to spread undetected.
This collaboration comes at a moment when demand for trustworthy AI is rising. Regulators in multiple regions are exploring laws requiring audit trails and proof of compliance for AI tools. Having verifiable metadata and automated scanning helps organizations prepare for that future. For developers working with open-source models, this means better peace of mind and fewer surprises when integrating AI into systems.

Another benefit is reproducibility. When researchers publish a model, the additional metadata will include not just code but the entire set of conditions under which it was trained—hardware setup, software versions, preprocessing scripts, and dataset hashes. This helps other researchers validate results and catch hidden issues.
There’s also a community angle. Hugging Face and JFrog are both known for promoting open ecosystems. Keeping this process open—rather than locking it behind paid products or private audits—enables community-based oversight. Users can flag suspicious models, report issues, or suggest improvements to metadata fields. It's a crowdsourced approach that builds resilience through participation rather than gatekeeping.
For enterprises, this move aligns with how software development is already managed. DevOps teams using tools like Artifactory or Xray can now extend their workflows to include model artifacts. This brings AI under the same security umbrella as traditional software, closing a major compliance and risk gap.
This partnership between Hugging Face and JFrog isn't about new algorithms or AI performance benchmarks. It's about fixing the plumbing—making sure the tools we use are secure, documented, and traceable. This move toward transparent model sharing is overdue in a space that often rewards speed over caution. The focus on AI security isn't just for big enterprises—it matters for any developer working with a model, whether for a chatbot or healthcare. By targeting open-source models, the collaboration has a broad and immediate impact. Security doesn’t have to slow innovation—it just needs to be part of the process.
Advertisement
How temporal graphs in data science reveal patterns across time. This guide explains how to model, store, and analyze time-based relationships using temporal graphs

How stochastic in machine learning improves model performance through randomness, optimization, and generalization for real-world applications

How LLM evaluation is evolving through the 3C3H approach and the AraGen benchmark. Discover why cultural context and deeper reasoning now matter more than ever in assessing AI language models

How to run LLM inference on edge using React Native. This hands-on guide explains how to build mobile apps with on-device language models, all without needing cloud access

Access to data doesn’t guarantee better decisions—culture does. Here’s why building a strong data culture matters and how organizations can start doing it the right way

Looking to master SQL concepts in 2025? Explore these 10 carefully selected books designed for all levels, with clear guidance and real-world examples to sharpen your SQL skills

Explore how π0 and π0-FAST use vision-language-action models to simplify general robot control, making robots more responsive, adaptable, and easier to work with across various tasks and environments
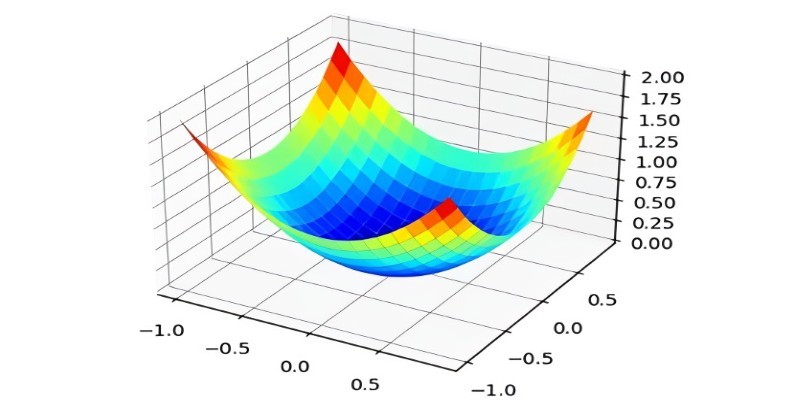
What the Adam optimizer is, how it works, and why it’s the preferred adaptive learning rate optimizer in deep learning. Get a clear breakdown of its mechanics and use cases

Language modeling helps computers understand and learn human language. It is used in text generation and machine translation

How AI-powered earthquake forecasting is improving response times and enhancing seismic preparedness. Learn how machine learning is transforming earthquake prediction technology across the globe

How Open-source DeepResearch is reshaping the way AI search agents are built and used, giving individuals and communities control over their digital research tools

How Monster API simplifies open source model tuning and deployment, offering a faster, more efficient path from training to production without heavy infrastructure work