Advertisement
Open-source AI models are everywhere now. From casual users experimenting with small language models to researchers fine-tuning transformers for niche tasks, the accessibility has grown fast. But training and fine-tuning these models is only half the job. Getting them into production, especially in real-world applications, often turns into a slow grind.
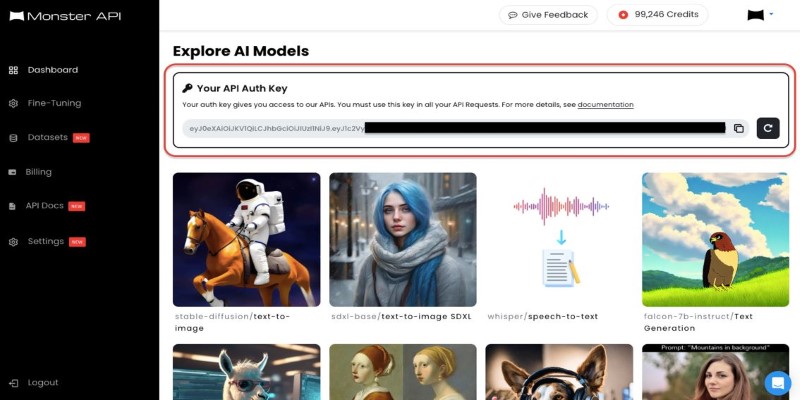
That’s where Monster API comes in. It strips away much of the frustration around model deployment, offering a way to move from experimentation to execution without dragging teams through complex DevOps or infrastructure work. It meets developers and small teams right where they are.
Plenty of open-source models are fine on their own. But for most users, "fine" isn't useful. Custom tasks, such as medical report summarization, regional sentiment analysis, or brand-specific tone modeling, require models trained on private or curated datasets. That means fine-tuning. And while tools like Hugging Face, PyTorch, and bits and bytes make this accessible, there's a clear wall: the hardware needed to fine-tune a model like LLaMA 2 or Mistral-7B isn’t cheap. Even running inference reliably becomes a stretch. Many developers start training only to realize midway they’re short on RAM, storage, or GPU cycles.
Monster API gives users a path forward by making high-performance infrastructure available without the headache. It lets you fine-tune models in the cloud with pre-configured environments that support quantization, adapters like LoRA, and efficient resource scheduling. You can bring your dataset or use public ones, then monitor everything through a clean web interface or CLI. There's no need to spin up cloud instances, install CUDA libraries, or build Docker containers from scratch. That’s the gap it fills: technical flexibility without the infrastructure drag.
Fine-tuning is one kind of work. Deploying a model so users can actually use it is another. Many open-source projects stall here. Developers get the model working locally but never find a clean, cost-efficient way to put it behind an API or a UI. Hosting services like AWS or Azure are powerful but come with their own set of problems: vendor lock-in, steep learning curves, and often a mismatch between what developers need and what the platform assumes.

Monster API handles this by turning any fine-tuned model into an API endpoint with one click. It can automatically wrap the model with basic inference logic, manage scaling, and even provide token-based access. This means a developer working on a fine-tuned LLaMA model for customer support can go from training to a live endpoint in minutes, not days. It’s especially useful for teams without a dedicated MLOps engineer. Everything is abstracted but still configurable, allowing you to deploy multiple versions, rollback updates, and monitor usage in real-time.
What makes this more interesting is its support for fine-grained hardware selection. Instead of paying for generic compute instances, users can choose GPUs based on model size and expected usage. If you’re testing something lightweight, you can use a T4. For heavy inference workloads, jump to A100s. It’s a flexible way to control costs while scaling up when needed.
One of the more practical aspects of Monster API is its ability to serve small teams. Most cloud platforms are built with large enterprises in mind. They assume scale, budget, and staff. But the real explosion of interest in open-source AI is happening among indie developers, startups, and research labs. Monster API supports this middle ground well. You can train a model on customer queries, legal documents, or even agricultural sensor data, then serve it from a stable endpoint that doesn’t require 24/7 babysitting.
Its CLI and Python SDK are both straightforward. You can script everything from fine-tuning to deployment. Want to automate the retraining process based on fresh incoming data? That's supported. Prefer to update model parameters incrementally using adapters instead of full retrains? That's available, too. And since the models are hosted in secure, isolated containers, you don't need to worry about exposing sensitive information during inference.
Another overlooked feature is the billing model. Unlike generic cloud computing that charges by the hour whether or not you use the GPU, Monster API charges based on active use. You're not locked into long-term commitments, and you can scale down without penalty. This encourages experimentation, especially for use cases that require only short bursts of computing, such as document processing, translation, or summary generation on demand.
Monster API doesn't just simplify things; it redefines the workflow for deploying AI models. Instead of splitting efforts between training code, DevOps scripting, and performance optimization, teams can focus on the model and the data. Once that's done, deployment becomes a linear step, not a separate project. This shifts how teams think about model delivery, making it iterative, testable, and more fluid.
The platform also integrates well with existing tools. Want to use Hugging Face Transformers? It works out of the box. Need logging and observability for your deployed model? There’s built-in support for standard metrics and log hooks. You can version your models, control user access, and even track inference latency — all without writing a single line of server code.
Monster API doesn't try to reinvent the entire ML stack. It just fills in the missing pieces — mostly around deployment and management. And in doing so, it brings open-source model workflows closer to production readiness. For developers working outside big tech companies, this makes all the difference. You're not building infrastructure just to test your idea. You're testing it directly on the real thing, with fewer steps and cleaner feedback.
Monster API simplifies the often clunky process of going from fine-tuned open-source models to real-world deployment. Instead of adding more tools, it streamlines the path with fast deployment options, flexible infrastructure, and minimal overhead. Whether you're building a chatbot, a content tool, or an internal AI service, it helps you move quickly without needing a big stack or complex setup. For developers and small teams, it shifts the focus from infrastructure headaches to actually using AI where it counts.
Advertisement

How Monster API simplifies open source model tuning and deployment, offering a faster, more efficient path from training to production without heavy infrastructure work

How Open-source DeepResearch is reshaping the way AI search agents are built and used, giving individuals and communities control over their digital research tools

How Krutrim became India’s first billion dollar AI startup by building AI tools that speak Indian languages. Learn how its large language model is reshaping access and inclusion

AI interference lets the machine learning models make conclusions efficiently from the new data they have never seen before

Explore the Rabbit R1, a groundbreaking AI device that simplifies daily tasks by acting on your behalf. Learn how this AI assistant device changes how we interact with technology

Access to data doesn’t guarantee better decisions—culture does. Here’s why building a strong data culture matters and how organizations can start doing it the right way

Looking for the best podcasts about generative AI? Here are ten shows that explain the tech, explore real-world uses, and keep you informed—whether you're a beginner or deep in the field

Gradio's new data frame brings real-time editing, better data type support, and smoother performance to interactive AI demos. See how this structured data component improves user experience and speeds up prototyping
How Math-Verify is reshaping the evaluation of open LLM leaderboards by focusing on step-by-step reasoning rather than surface-level answers, improving model transparency and accuracy

How AI-powered earthquake forecasting is improving response times and enhancing seismic preparedness. Learn how machine learning is transforming earthquake prediction technology across the globe

How One Hot Encoding converts text-based categories into numerical data for machine learning. Understand its role, benefits, and how it handles categorical variables

How the LiveCodeBench leaderboard offers a transparent, contamination-free way to evaluate code LLMs through real-world tasks and reasoning-focused benchmarks