Advertisement
Most people don't think about how machines read data. They see categories like “Red,” “Blue,” or “Green” and assume that’s fine. But to a machine, those are just labels without meaning. You can’t plug “Green” into an equation and get something useful. And yet, many datasets include exactly that type of input.
If we want a machine to learn from it, we need a way to turn words into numbers without twisting their meaning. That’s where one hot encoding steps in. It’s a small but essential technique for making real-world data readable by models.
One hot encoding converts categorical variables into a model-ready format. Models process numbers, not text. If there are values like "Apple," "Banana," and "Grape" in a column, the algorithm can't calculate with that. One hot encoding fixes this by adding new binary columns. Each is for a category. A row receives a "1" in the column corresponding to its value and a "0" in the rest.
So for a “Color” column with Red, Green, and Blue, you’d get three new columns: Color_Red, Color_Green, and Color_Blue. Each row gets a single “1” in the right place.
This avoids the mistake of label encoding, which assigns numbers like Red = 1, Green = 2, Blue = 3. That approach falsely implies some kind of rank or scale. One hot encoding keeps the categories equal and unrelated, which is often exactly what you want.
It’s especially useful for non-ordinal categories—those that don't have a natural order. Job titles, city names, and product IDs fall into this group.
One hot encoding works best with non-ordinal categorical variables. Values like "Truck," "Car," or "Bike " have no natural rank, so using a numeric label for these might mislead the model. One hot encoding avoids this risk by treating each category separately.
It's commonly used when training models on structured data, such as spreadsheets or CSVs. Whether you're working with linear regression, decision trees, or ensemble methods, this encoding ensures the model interprets your data correctly.
There is a tradeoff. One hot encoding increases the number of features in your dataset. A column with 100 unique values becomes 100 new binary columns. This is fine for small datasets but becomes problematic with high-cardinality features like zip codes or user IDs. It can slow down training, eat up memory, and cause overfitting.
To deal with that, you can group rare categories into an “Other” label before encoding. Some workflows replace one hot encoding with embeddings or hashing tricks, especially when working with deep learning. But for most classical machine learning tasks, one hot encoding remains a reliable starting point.
Let’s go through a simple example using Python and pandas.
Suppose you have a DataFrame with a column “Animal” containing “Dog,” “Cat,” and “Rabbit”:
import pandas as pd
df = pd.DataFrame({
'Animal': ['Dog', 'Cat', 'Rabbit', 'Dog', 'Cat']
})
You can one hot encode it with:
encoded_df = pd.get_dummies(df, columns=['Animal'])
Your DataFrame now looks like this:
Animal_Cat Animal_Dog Animal_Rabbit
0 0 1 0
1 1 0 0
2 0 0 1
3 0 1 0
4 1 0 0
Each row has a “1” in the column that matches its original value. Everything else is “0.”
For more complex workflows, especially if you're using scikit-learn, you might prefer OneHotEncoder. It allows more control and works well in pipelines:
from sklearn.preprocessing import OneHotEncoder
encoder = OneHotEncoder(sparse=False, drop='first')
encoded = encoder.fit_transform(df[['Animal']])
This drops the first category to avoid redundancy—the dummy variable trap.
If you’re dealing with several categorical variables, you can hot encode them all simultaneously. Pass the full list to get_dummies() or use ColumnTransformer with OneHotEncoder inside a pipeline.
The process is straightforward. The key is knowing when it fits and when to consider other options, especially if your categorical variables have too many levels.
In real projects, one hot encoding often happens early in the workflow. It usually sits in the data preprocessing phase before training begins. While it’s not the most advanced technique, it’s one of the most used.

One hot encoding is essential for linear models, which assume a linear relationship between input features and outputs. The model could draw misleading conclusions if a categorical variable is wrongly encoded with labels. One hot encoding avoids this and supports independent feature contribution.
The effect is mixed for decision trees and ensemble models like random forests or gradient boosting. These models can sometimes handle categorical inputs directly. Still, one hot encoding ensures consistency and often improves performance when categories are few.
In deep learning, high-cardinality features are often embedded instead. But even in neural networks, one hot encoding is still used for low-cardinality features. It's also used for output layers in classification tasks, where each class gets its node.
The method fits almost any environment where categorical variables exist. It doesn’t add complexity, and its results are easy to interpret. This simplicity is part of why it’s so widely adopted.
One hot encoding is a practical solution for converting categorical variables into a usable format for machine learning models. It creates clear, binary representations that avoid false assumptions about order or relationship between categories. This makes it ideal for structured data with non-ordinal labels. Though it increases dimensionality, its simplicity and reliability make it one of the most commonly used preprocessing steps. Whether you’re working with regression, classification, or tree-based models, one hot encoding helps ensure the data is interpreted correctly. It’s not complex, but it’s essential for models that rely on clean and structured numerical input.
Advertisement

How One Hot Encoding converts text-based categories into numerical data for machine learning. Understand its role, benefits, and how it handles categorical variables

How the LiveCodeBench leaderboard offers a transparent, contamination-free way to evaluate code LLMs through real-world tasks and reasoning-focused benchmarks

AI interference lets the machine learning models make conclusions efficiently from the new data they have never seen before

How Voronoi diagrams help with spatial partitioning in fields like geography, data science, and telecommunications. Learn how they divide space by distance and why they're so widely used

Hugging Face and JFrog tackle AI security by integrating tools that scan, verify, and document models. Their partnership brings more visibility and safety to open-source AI development
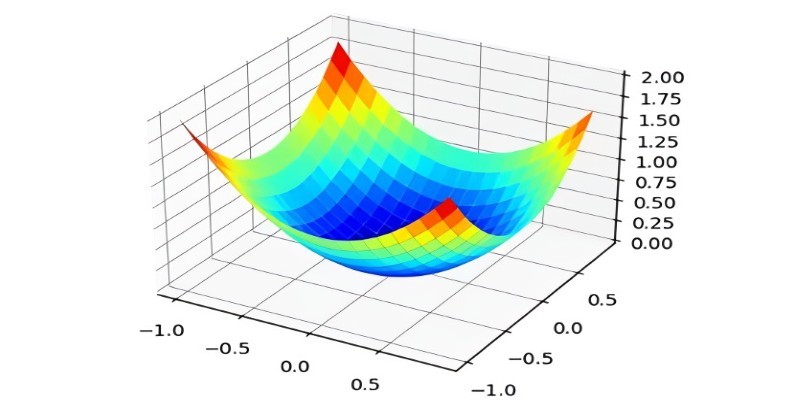
What the Adam optimizer is, how it works, and why it’s the preferred adaptive learning rate optimizer in deep learning. Get a clear breakdown of its mechanics and use cases

Explore the Rabbit R1, a groundbreaking AI device that simplifies daily tasks by acting on your behalf. Learn how this AI assistant device changes how we interact with technology

Gradio's new data frame brings real-time editing, better data type support, and smoother performance to interactive AI demos. See how this structured data component improves user experience and speeds up prototyping

What data annotation is, why it matters in machine learning, and how it works across tools, types, and formats. A clear look at real-world uses and common challenges

Natural language generation is a type of AI which helps the computer turn data, patterns, or facts into written or spoken words
Learn how to bake vertex colors into textures, set up UVs, and export clean 3D models for rendering or game development pipelines
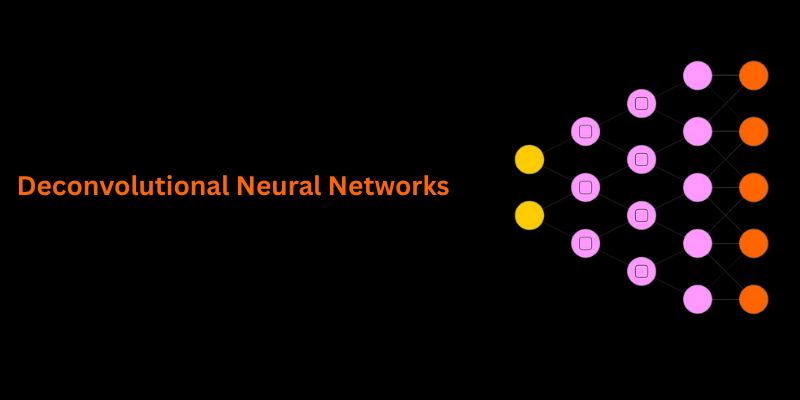
Understand how deconvolutional neural networks work, their roles in AI image processing, and why they matter in deep learning