Advertisement
Deconvolutional neural networks play a critical role in deep learning tasks related to image generation and analysis. These models reconstruct input data from processed features by applying reversed convolutional operations. They are widely used in applications such as image synthesis, semantic segmentation, and feature visualization. Understanding deconvolutional neural networks enhances the performance and transparency of AI systems.
These networks offer deeper insights into data structures and hidden layers, helping developers interpret the activations of individual neurons during training. This interpretability supports effective debugging and improves overall model transparency. Additionally, deconvolutional layers are essential for upsampling and enhancing image quality, complementing traditional convolutional layers by enabling inverse transformations.
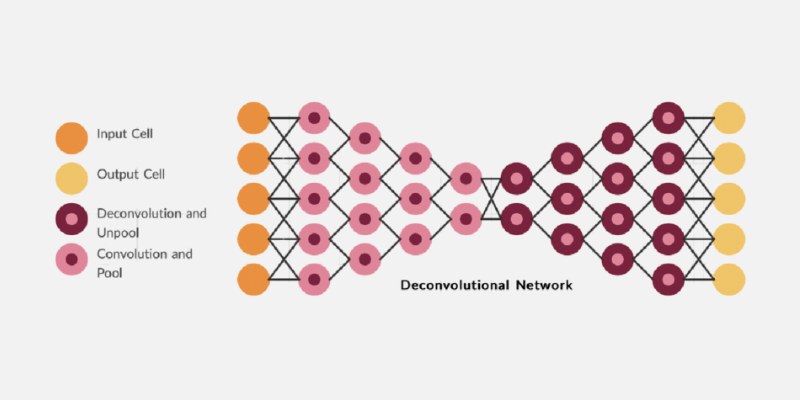
Deconvolutional neural networks are structured to reverse convolution effects, reconstructing images from abstract feature maps. While convolutional layers compress spatial data into features, deconvolutional layers expand them back to their original scale. A deconvolutional layer returns it to its original scale. Visualizing deep learning aspects depends on this technique. Though they use inverse operations, their design mirrors that of convolutional models. They are often referred to as transposed convolutional networks. They increase image resolution during data upsampling. Instead of extracting features, they reinterpret them into higher-resolution representations.
These networks help with chores that require spatial accuracy. Their architecture includes components like unspooling, rectification, and filtering. A solid understanding of Deconvolution is essential for building robust computer vision systems. It also facilitates artificial intelligence network interpretability. Autoencoders and generative models commonly feature deconvolutional layers. Engineers use them for image restoration, among other purposes. In visual data reconstruction, they are rather effective tools. That makes them indispensable in image analysis and synthesis.
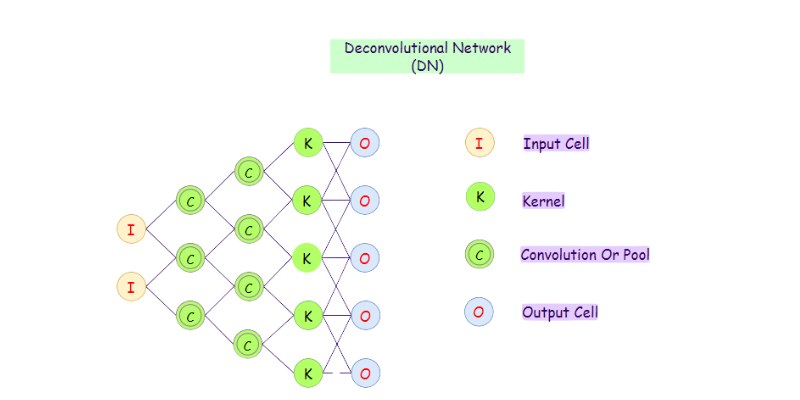
Convolution filters significant spatial information and, therefore, compresses data. Deconvolution reverses this process. It generates higher-density images from low-resolution data. Convolutions find edges and patterns. Original images from those features are rebuilt in deconvolutional layers. Both play different roles in deep learning pipelines. Moving a filter across an image, a convolution operation aggregates pixel regions. A deconvolution expands limited data using learned filters. Both approaches have opposite purposes.
Convolution facilitates classification, while deconvolution aids in reconstruction. One compresses information; the other restores it. Models like autoencoders and GANs operate within deconvolution architectures, which involve strides, padding, and filter flipping. Unlike convolution, output size grows. Though they have different directions and goals, they share ideas. Deconvolution excels at pixel-wise predictions and generating semantic maps. These variations allow engineers to create intricate artificial intelligence models. Knowing this helps to improve segmentation techniques and image restoration. The correct application increases model interpretability and precision.
Deconvolutional neural networks let developers see internal AI model representations. From learned features, these layers rebuild input images. They reveal the activity of each neuron during training. They help researchers understand how models interpret objects. Visualizations help to increase AI trust and openness. These networks help model debugging. They identify regions where information may be lost or misinterpreted. Feature maps are converted into understandable graphic language. It contributes to building more robust models.
Visual outputs provide an understanding of the priorities among layers. Designers can then adjust model parameters to suit. CNN feature viewing benefits from Deconvolution. It reveals hidden layer patterns. This method is applied in tools including feature inversion and guided backpropagation. Its application is in scene detection and facial identification. It offers comments regarding the success of the training. Such visual instruments help to improve model decisions. They help both users and developers of artificial intelligence systems to understand them.
Deconvolutional networks produce high-resolution images from low-dimensional data particularly well. These models drive autoencoders and GANs, among other things. Deconvolution layers in picture upsampling expand image size without sacrificing quality. In super-resolution applications, they are vital. Unlike basic scaling, they learn to fill in missing pixel details, resulting in clearer, more realistic images. Generative models use deconvolution layers to build images step by step. Every layer enhances the outcome.
Levels of Deconvolution provide output images with semantic structure, making them useful in producing thorough artificial intelligence graphics. The technique allows for crisp changes in texture and enables lifelike human faces and environments. These features help picture-to-image translating systems. Jobs like turning sketches into colored graphics depend on them. Their accuracy guarantees scalable, consistent image synthesis. Deconvolution represents intelligent image expansion, not mere upsampling. That forms the backbone of several graphic-generating systems used nowadays.
Semantic segmentation calls for exact image pixel labeling. It is made feasible with deconvolutional networks. They convert low-resolution feature maps into tagged, full-resolution outputs. Each pixel is assigned to a specific class or category. The method guarantees precise object and border lines. Deconvolution layers define high-resolution forecasts. These layers preserve output map spatial correctness. Such layers define models such as U-Net and FCN. They provide segmentation architectures and their structural basis—deconvolution layers up sample intermediate outputs.
It lets every pixel match the original image positions, resulting in maps of separate items, backgrounds, and areas. This precision is crucial in health, robotics, and autonomous driving. Many times, segmentation models chain several deconvolution layers. These networks accurately reconstruct objects, benefiting from pixel-level attention in recognition tasks. In real-world settings, spatial awareness helps interpret scenes. Deconvolution improves the model's grasp of visual context. It supports wise and safe artificial intelligence decisions.
Though they have many advantages, deconvolutional networks also provide technological difficulties. One problem in photographs is checkerboard relics. Upsampling procedures cause these aberrations. Inappropriate kernel sizes or strides can produce unequal results. To avoid such flaws, models must be carefully tuned. Training deconvolutional networks is also computationally expensive. Deconvolution operations consume additional processing capability and memory. Poorly initialized layers can lead to noisy or distorted outputs. Another issue arising from too close reconstruction of training data is overfitting.
Sometimes, deconvolution networks muddy sharp edges. Perfecting filters becomes essential for clarity. Interpreting outcomes can still be difficult for some jobs. Filter design and network depth define accuracy. Generative models allow training instability. Frequent hyperparameter tuning is often required. The selection of appropriate loss functions is quite important.
Improving image reconstruction and data visualization depends most definitely on deconvolutional neural networks. To reconstruct spatial features in images, they flip convolution processes. Deep learning systems depend on them, especially in picture segmentation, visual interpretation, and upsampling. Training these networks poses challenges, and parameter tuning must be handled carefully. Designed well, these models increase model transparency and accuracy. Deconvolution continues to inspire innovation in image processing. Deep learning deconvolution networks will continue to be essential tools for intelligent systems and advanced computer vision applications as artificial intelligence develops.
Advertisement

How AI-powered earthquake forecasting is improving response times and enhancing seismic preparedness. Learn how machine learning is transforming earthquake prediction technology across the globe

How One Hot Encoding converts text-based categories into numerical data for machine learning. Understand its role, benefits, and how it handles categorical variables

How stochastic in machine learning improves model performance through randomness, optimization, and generalization for real-world applications

What data annotation is, why it matters in machine learning, and how it works across tools, types, and formats. A clear look at real-world uses and common challenges

How the LiveCodeBench leaderboard offers a transparent, contamination-free way to evaluate code LLMs through real-world tasks and reasoning-focused benchmarks

Access to data doesn’t guarantee better decisions—culture does. Here’s why building a strong data culture matters and how organizations can start doing it the right way
How temporal graphs in data science reveal patterns across time. This guide explains how to model, store, and analyze time-based relationships using temporal graphs

How Voronoi diagrams help with spatial partitioning in fields like geography, data science, and telecommunications. Learn how they divide space by distance and why they're so widely used

How Open-source DeepResearch is reshaping the way AI search agents are built and used, giving individuals and communities control over their digital research tools

Discover the Playoff Method Prompt Technique and five powerful ChatGPT prompts to boost productivity and creativity

How to run LLM inference on edge using React Native. This hands-on guide explains how to build mobile apps with on-device language models, all without needing cloud access
How Math-Verify is reshaping the evaluation of open LLM leaderboards by focusing on step-by-step reasoning rather than surface-level answers, improving model transparency and accuracy